Code Mode: Rethinking MCP

What if, instead of giving your AI agent a menu of tools to pick from, you gave it an SDK and let it write code?
In our last post on context engineering, we talked about why every token in an LLM's context window needs to earn its spot. We explored how structural code intelligence beats text search, and how purpose-built MCP tools give AI agents a real understanding of your codebase instead of a pile of grep results.
But we glossed over something important: how those MCP tools are delivered to the agent matters just as much as what they do. And the standard approach to MCP tool calling has some fundamental scaling problems.
This post is about how we solved them. It's about Code Mode, a pattern that replaces traditional MCP tool calling with something far more powerful, and why we adopted it as the foundation of Constellation's MCP server.
How Traditional MCP Tool Calling Works
Let's start with the standard model. When an MCP server exposes tools to an AI agent, each tool gets a full definition: a name, a description, a JSON schema for its parameters, and type information for its response. The agent sees all of these definitions in its system prompt, picks the right tool for the job, fills in the parameters, and gets back a result.
For simple use cases, this works great. One tool, one call, one result. Clean and predictable.
But Constellation isn't a simple use case.
What Breaks at Scale
Constellation's code intelligence API has, today, 11 distinct operations: symbol search, symbol details, dependency analysis, dependents lookup, circular dependency detection, symbol usage tracing, call graph traversal, impact analysis, orphaned code detection, architecture overview, and a health check. Each one serves a different purpose. Each one has its own parameters and response shape.
In a traditional MCP setup, that means 11 separate tool definitions sitting in the system prompt. Every single conversation starts with the LLM processing all of those schemas, their descriptions, their parameter types, their response formats. That's a significant chunk of tokens consumed before the developer even asks a question.
But the token cost of definitions is just the beginning. The real problem shows up during multi-step analysis.
The Round-Trip Tax
Say an AI agent needs to answer a common question: "Is it safe to refactor the AuthService class?"
With traditional tool calling, here's what happens:
- Call
searchSymbolswith query "AuthService". The full response comes back into context, every matching symbol with all of its metadata. - The LLM reads the response, identifies the right symbol, and calls
getDependents. Another full response lands in context. - The LLM reads that response and calls
impactAnalysis. Yet another full response. - Finally, the LLM synthesizes everything and answers the question.
Three round-trips. Three full response payloads dumped into the context window. The LLM had to process each intermediate result in its entirety just to extract the few fields it actually needed for the next step. All of that intermediate data is still sitting in the context window, taking up space, adding noise, and pushing the model further from the signal that matters.
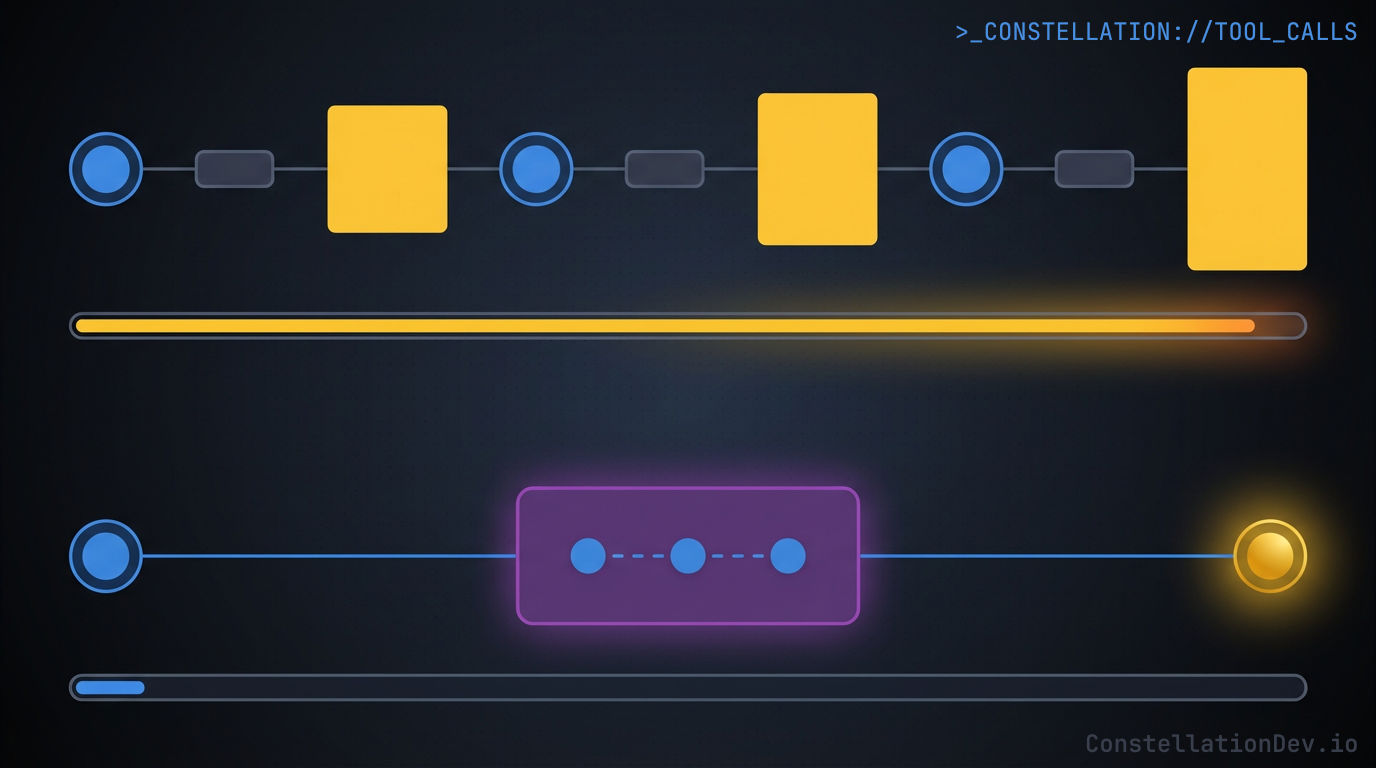
This is the round-trip tax, and it compounds quickly for any non-trivial analysis.
The Wrong Muscle
There's a deeper issue here too, and Cloudflare's engineering team articulated it perfectly: the special tokens used in tool calls are things LLMs have rarely seen in training data. LLMs learn from millions of real-world code examples, but they only encounter synthetic, contrived examples of tool-call formatting.
As Cloudflare put it, asking an LLM to work through tool calling is like putting Shakespeare through a crash course in Mandarin and then asking him to write a play in it. He'd manage, but it wouldn't be his best work.
You know what LLMs have trained on extensively? Code. Real, production JavaScript and TypeScript, with function calls, variable assignments, conditionals, and Promise.all(). Billions of examples.
What Is Code Mode?
Code Mode flips the model. Instead of exposing 11 separate tools, Constellation's MCP server exposes one tool called code_intel. That tool accepts a single parameter: JavaScript code.
The LLM writes code that calls an API object with methods like searchSymbols(), getDependents(), and impactAnalysis(). The code runs in a secure sandbox, executes against Constellation's code intelligence backend, and returns whatever the LLM's code constructs as its final expression.
That's it. One tool definition in the system prompt. One invocation per task. The LLM does what it does best: write code.
Why Constellation Chose Code Mode
We adopted Code Mode for two primary reasons, and both come back to the same principle we talked about in our context engineering post: making every token count.
1. Dynamic Composition
This is the big one. With Code Mode, the LLM isn't limited to pre-defined request/response patterns. It can compose arbitrarily complex queries by chaining API calls, using the results of one call to drive the next, running independent calls in parallel, and constructing a custom response object that contains only the data it needs.
Remember that "is it safe to refactor AuthService?" scenario? Here's what it looks like with Code Mode:
// Single code_intel invocation — one tool call, not three
const { symbols } = await api.searchSymbols({ query: "AuthService" });
const target = symbols[0];
// Parallel execution — both calls run simultaneously
const [dependents, impact] = await Promise.all([
api.getDependents({ filePath: target.filePath }),
api.impactAnalysis({ symbolId: target.id })
]);
// Custom response — only the fields the LLM actually needs
return {
symbol: target.name,
kind: target.kind,
file: target.filePath,
directDependentCount: dependents.directDependents.length,
risk: impact.breakingChangeRisk,
affectedFiles: impact.affectedFiles.map(f => f.filePath),
testFilesAffected: impact.affectedFiles
.filter(f => f.filePath.includes('.spec.'))
.map(f => f.filePath)
};
One tool call. One round-trip. The search result feeds directly into the parallel queries, and the final return statement shapes the response to include exactly what's needed for the refactoring assessment. No intermediate payloads bloating the context. No wasted tokens on fields the LLM doesn't care about.
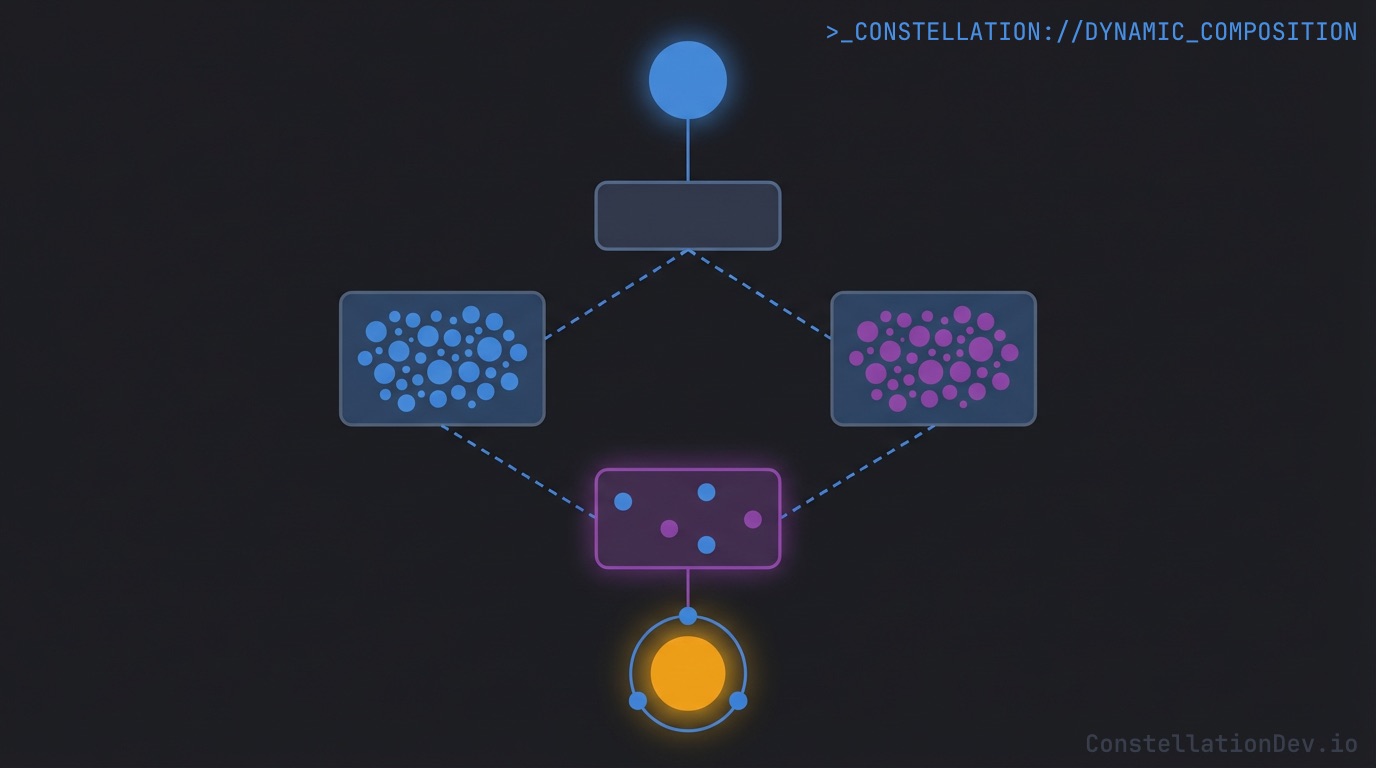
And this is a relatively simple example. In practice, agents compose much more sophisticated queries. Need to find all implementations of an interface, check each one for circular dependencies, and return only the problematic ones with their dependency chains? That's a single Code Mode invocation.
const { symbols } = await api.searchSymbols({ query: "PaymentProvider" });
const implementations = symbols.filter(s => s.kind === "class");
const results = await Promise.all(
implementations.map(async (impl) => {
const cycles = await api.findCircularDependencies({
filePath: impl.filePath
});
return { name: impl.name, file: impl.filePath, cycles: cycles.cycles };
})
);
// Only return the ones with actual circular dependencies
return results.filter(r => r.cycles.length > 0);
The LLM is doing programming. It's filtering, mapping, awaiting, and composing. This is square in its wheelhouse.
2. Token Economics
The second reason is pure arithmetic.
Definition overhead: Traditional MCP would put 11 tool schemas in the system prompt. With Code Mode, there's one tool definition plus a concise API reference describing the available methods. The savings scale linearly with the number of operations your server supports, and Constellation's operation count will only grow over time.
Response overhead: In a traditional multi-step flow, every intermediate response enters the context window in full. The LLM reads it, extracts what it needs, and moves on, but the full payload stays in context for the remainder of the conversation. With Code Mode, the sandbox processes those intermediate results internally. Only the final, LLM-curated response makes it back into the context window.
Cumulative savings: Over the course of a coding session with dozens of code intelligence queries, the token savings compound significantly. Cleaner context means the model stays sharper longer, hits compaction less frequently, and produces more accurate results. It's exactly the kind of context engineering we advocated for in our previous post, applied at the protocol level.
What This Means for Developers
If you're using Constellation with Claude Code, Cursor, Windsurf, or any MCP-compatible tool, you don't need to think about any of this. Code Mode is invisible to you. Your AI agent simply has access to a code_intel tool and uses it to understand your codebase.
But what you will notice is that your agent handles complex questions more fluidly. It answers "what depends on this?" and "what would break if I changed that?" in a single step instead of fumbling through multiple rounds of tool calls. It stays coherent further into long sessions because its context window isn't clogged with intermediate query results.
The agent writes better queries because it's writing code, the thing it was trained to do, instead of wrestling with structured tool-call syntax. And it returns tighter, more relevant answers because it controls the shape of every response.
The Bigger Picture
Code Mode isn't a Constellation invention. The pattern was pioneered by Cloudflare's Agents SDK team, and we expect it to gain traction across the MCP ecosystem as server developers hit the same scaling walls we did. The MCP standard provides the connectivity, authorization, and discoverability layer. Code Mode provides a better execution model on top of it.
For us, adopting Code Mode was a natural extension of the context engineering principles we've been building around. Constellation exists to give AI agents structural understanding of code without dumping raw source files into the context window. Code Mode extends that philosophy to the protocol layer itself: don't just deliver better answers, deliver them more efficiently.
As MCP servers grow more capable, as they expose more operations with richer response types, the traditional one-tool-per-operation model will strain under its own weight. Code Mode offers a path that scales, and does so by leaning into what LLMs already do well.
At ShiftinBits we're building Constellation, the shared code intelligence layer for AI coding agents. Constellation maintains a team-wide knowledge graph of your codebase and exposes it to tools like Claude Code, Cursor, GitHub Copilot, and Windsurf via the Model Context Protocol (MCP), giving them structural understanding of your code with symbol-level search, dependency graphs, impact analysis, and more.
If you're building with AI coding tools and want to see what your agents can do with real code intelligence, check out Constellation. For a limited time, we're giving early adopters 50% off with the promo code ROOTNODE50.