One Index: The Case for Shared Code Intelligence

Your codebase has one architecture. Why does every developer's AI agent build its own private mental model of it?
The last few posts in this series have focused on what goes into an AI agent's context window: why structural code intelligence beats text search, how Code Mode collapses multi-step queries into a single efficient round-trip, and how plugins encode team knowledge as reusable primitives. But most AI coding tooling shares a quiet assumption: code intelligence is a per-developer artifact. Every engineer builds their own snapshot of the codebase and queries it alone.
That model made sense when AI coding tools were still finding their footing. For teams working on serious codebases, it's starting to show its limits.
The Problem with Stateless Intelligence
Without a dedicated code intelligence layer, AI agents understand your codebase the same way a developer would on their first day: by reading files. They grep for keywords, open whatever looks relevant, and build a working picture from whatever fits in context. Some tools supplement this with embeddings or editor-maintained indexes for smarter file retrieval, but the fundamental model is the same: each session starts cold, re-derives what it needs, and discards it when done.
For a solo developer on a small repo, this is workable. But scale it up to a real team on a real codebase, and a few problems compound.
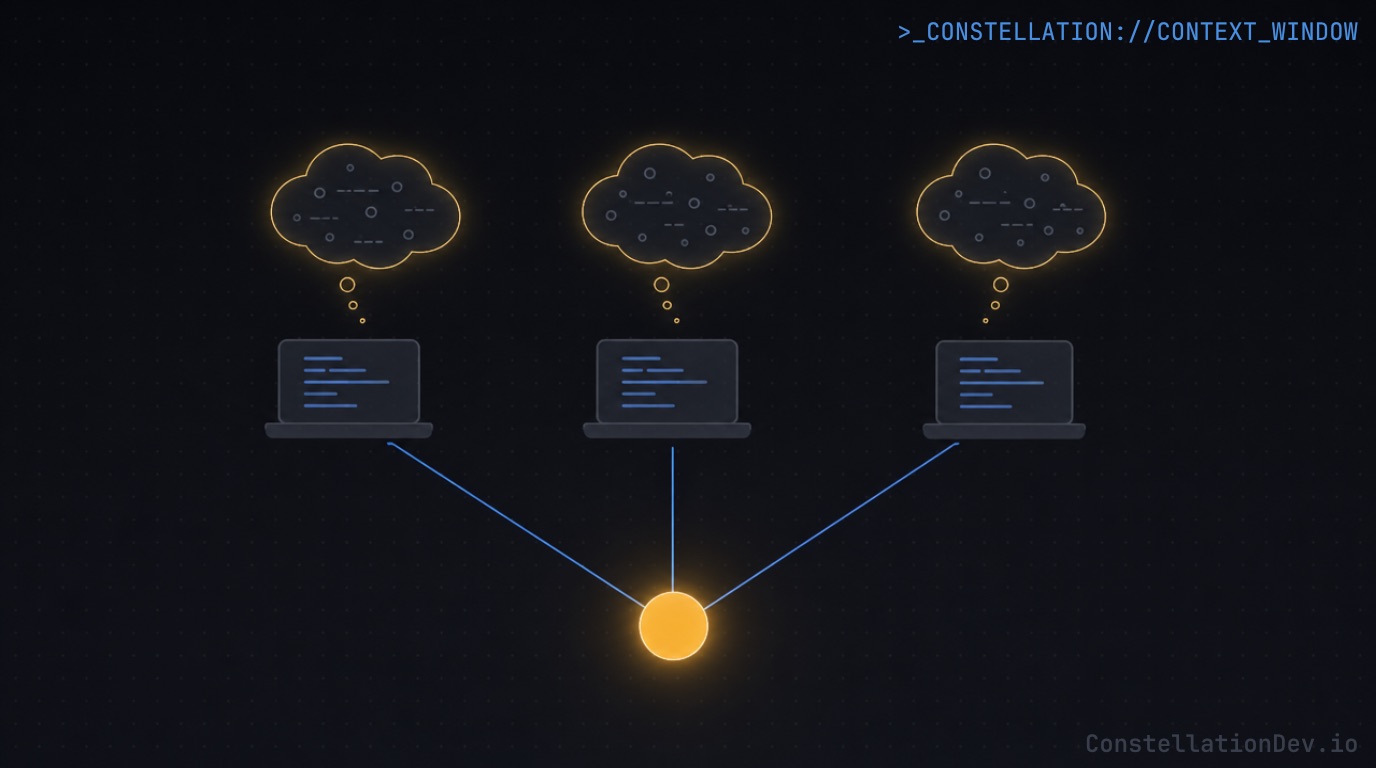
Every session starts from scratch. There's no persistent structural understanding that carries over between sessions or between teammates. An agent that traced a dependency chain yesterday has no memory of it today. A teammate's agent that answered the same question an hour ago did the same work independently and produced its own answer, which may or may not match.
Answers drift between teammates. When agents derive understanding on demand from whatever files they happen to read, two agents asking the same structural question can reach different conclusions depending on which files they opened, which branch they're on, and how much context they had room to work with. That drift is invisible until it surfaces in a code review, a pairing session, or a debate about whether a refactor is safe.
Onboarding gets no head start. A new engineer's agent arrives knowing nothing about the codebase and has to discover everything from file reads and whatever instruction documents the team maintains. The team's accumulated understanding of the system (which modules are load-bearing, which dependencies are fragile, where the hot spots are) lives in people's heads, not anywhere an agent can query.
What a Shared Layer Actually Looks Like
The alternative is simple: one code intelligence layer, maintained centrally, queried by everyone.
In practice:
- A single canonical knowledge graph for the codebase, kept up to date as code lands on trunk.
- Every consumer (Claude Code, Cursor, Copilot, Windsurf, a CI pipeline) queries the same graph through a standard protocol.
- No individual responsibility for maintaining the index. That job belongs to CI pipelines.
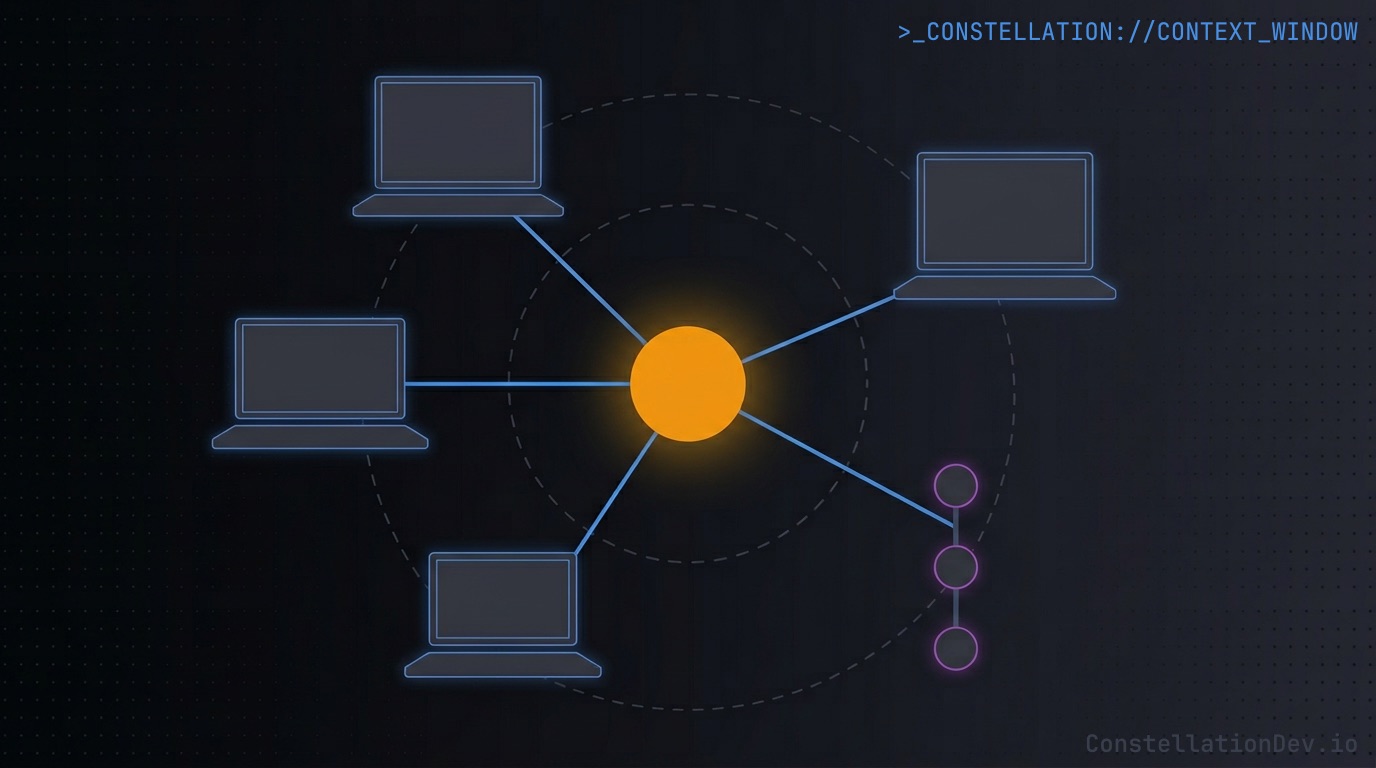
This is the architecture Constellation is built around. Each project is configured with a trunk branch name. The CLI extracts structural metadata locally and uploads it on push or merge to that branch. Constellation maintains the knowledge graph server-side, and every MCP-compatible tool on the team queries that one graph.
A few design constraints make this work:
- Privacy first: The CLI extracts only structural metadata (symbol names, relationships, complexity metrics, file paths) and never raw source. A shared layer that requires uploading source code is a non-starter for most teams.
- Trunk-scoped: The graph reflects the team's trunk branch and only that branch. Code earns its way into the shared brain by merging. Until then, in-flight work lives on the developer's local branch where it belongs. A graph polluted by every developer's half-finished feature branch quickly loses its value as a source of truth.
- Open protocol: Access goes through MCP, so any compatible tool works, not just one vendor's tooling.
What Changes for the Team
Day-zero fluency for new hires
A new engineer on day one authenticates to Constellation and their agent is immediately working from the same graph as the most senior person on the team. Symbol search, dependency analysis, impact analysis, architecture overview: all of it on day zero.
The human still has to ramp up on the team's domain, conventions, and history. But the tooling doesn't. It inherits the team's accumulated understanding of the codebase the moment it connects, because the graph was already there.
On large codebases where building a mental model is the slow part of onboarding, that matters.
Consistent answers across the team
When every agent queries the same graph, every agent gives the same shape of answer. The reviewer's "what depends on this?" matches the author's. A pair-programming session converges on a shared picture instead of two divergent ones. The debate about whether a refactor is safe gets settled with a single query everyone trusts, because everyone is looking at the same thing.
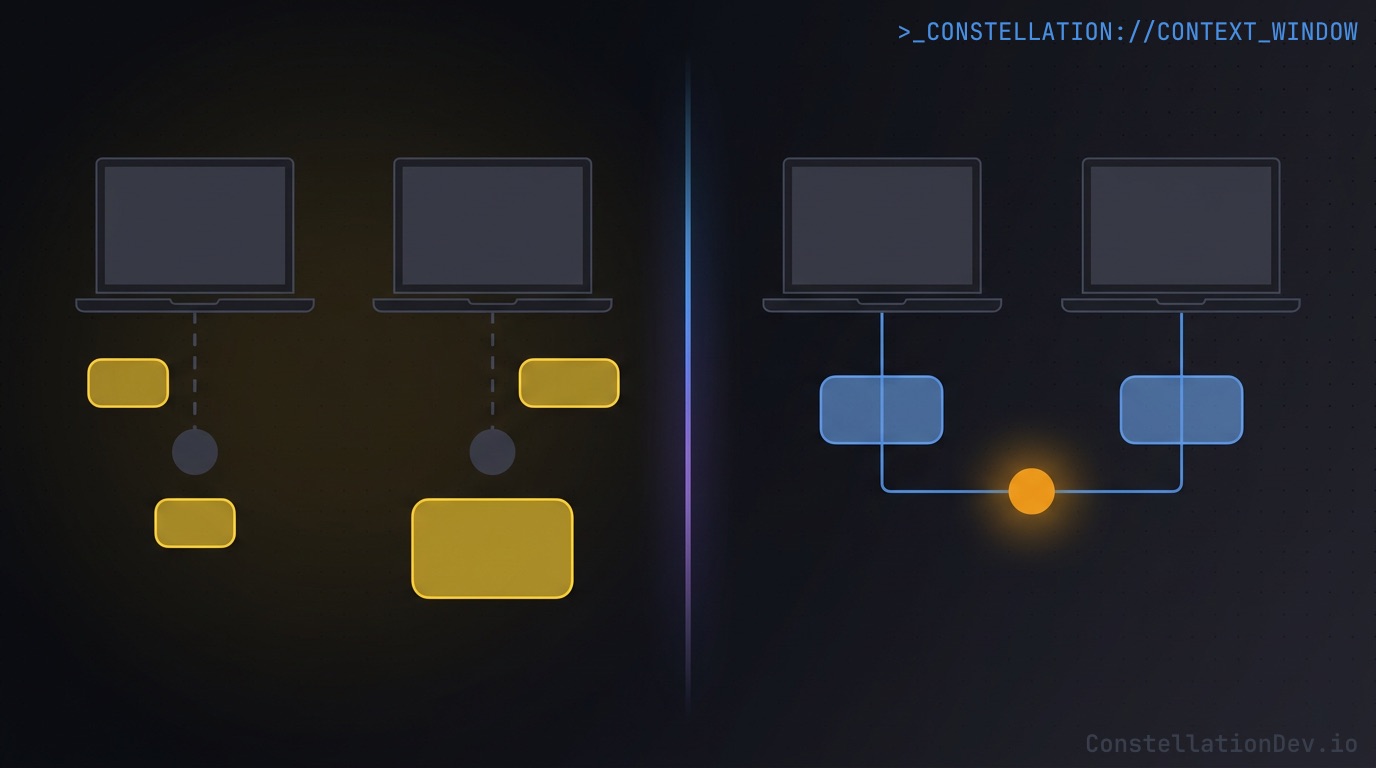
It removes a category of friction that's easy to ignore: the "Patrick's AI says X, but Bobby's says Y, which is right?" moments that crop up in code reviews, pairing sessions, and architectural discussions when everyone's intelligence layer is slightly out of sync.
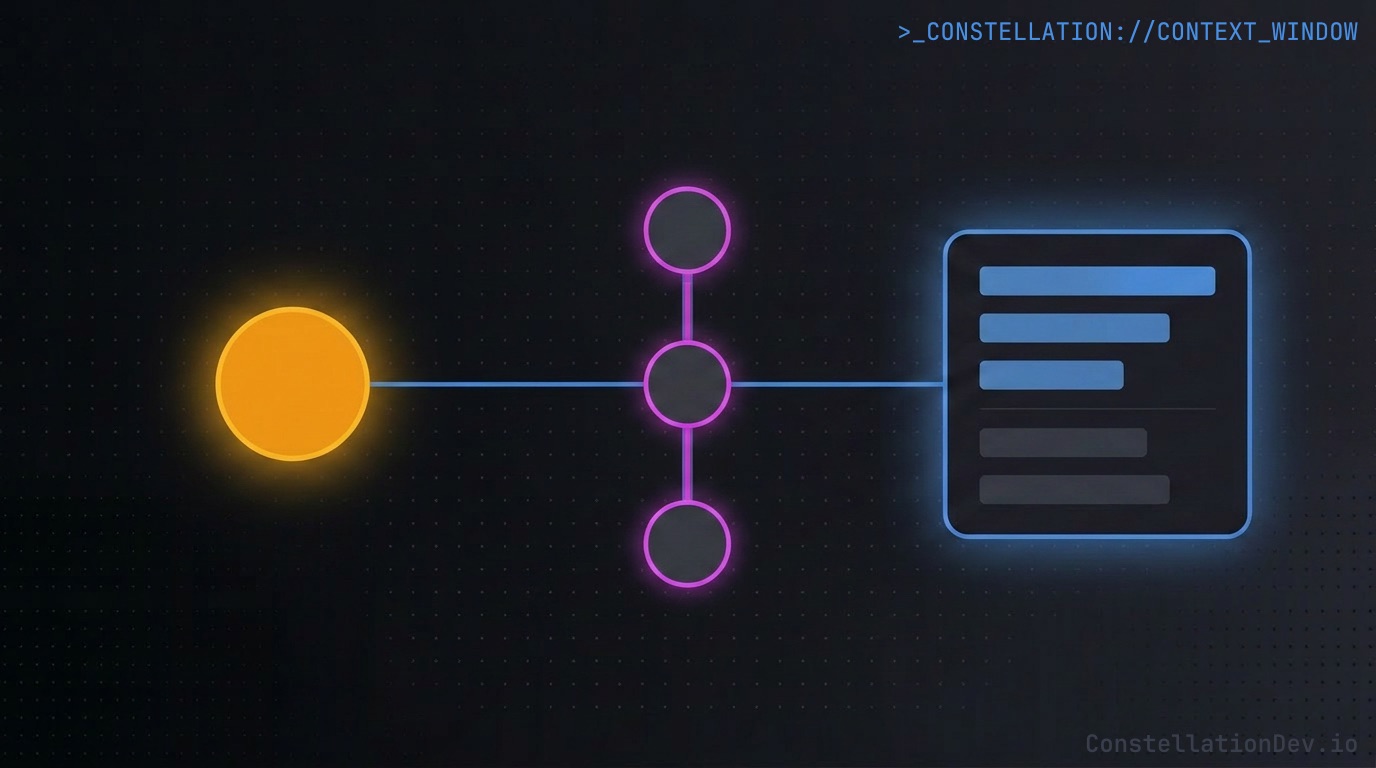
CI becomes a first-class participant
Once code intelligence is centralized, CI can use it too, and not just to update the index. A pre-merge job can query the graph for the impact of a PR's changes and post a structured comment: "this change touches a function with 14 transitive dependents across 6 files, including 3 test files." A nightly job can surface newly orphaned code introduced by recent merges. A migration script can verify that every reference to a deprecated symbol has actually been removed before running.
None of this requires CI to re-implement code analysis. It queries the same graph the developers' editors do. The intelligence layer becomes a shared platform for humans, agents, dashboards, and pipelines, not a feature locked inside any one IDE.
The Bottom Line
The first wave of AI coding tools optimized for the individual developer: better autocomplete, smarter chat, faster edits. That was the right place to start, and it's still where most of the visible polish lives.
But codebases are shared artifacts, and the intelligence that helps teams navigate them should be too. When code intelligence is centralized, indexed by CI on every trunk merge, and accessible to every tool through an open protocol, onboarding compresses, drift disappears, and CI gets capabilities that were previously out of reach.
One brain, many developers. Small shift, large blast radius.
At ShiftinBits we're building Constellation, the shared code intelligence layer for AI coding agents. Constellation maintains a team-wide knowledge graph of your codebase and exposes it to tools like Claude Code, Cursor, GitHub Copilot, and Windsurf via the Model Context Protocol (MCP), giving them structural understanding of your code with symbol-level search, dependency graphs, impact analysis, and more.
If you're building with AI coding tools and want to see what your agents can do with real code intelligence, check out Constellation. For a limited time, we're giving early adopters 50% off with the promo code ROOTNODE50.